NeuNet
la rappresentazione geometrica delle reti neurali

"Per trattare iperpiani in uno spazio a 14 dimensioni, visualizza uno spazio tridimensionale e di «quattordici» a te stesso molto forte."
Le reti neurali vengono spesso considerate delle "black box", delle scatole magiche che riescono a fare quello che fanno senza che si possa capire come lo fanno. Certamente le reti neurali usate per risolvere problemi reali sono costituite da un numero tale di elementi (neuroni e sinapsi) da renderne difficile l'analisi e soprattutto capirne i difetti quando qualcosa va storto. Basta pensare che già una semplice rete per riconosce cifre scritte a mano libera in piccole immagini di dimensione 20 x 20 come in questo mio piccolo esperimento, può tranquillamente arrivare ad avere 41000 sinapsi. Immaginate una rete neurale in grado di guidare un'automobile! Ma il problema è quantitativo, non qualitativo. Il funzionamento delle reti neurali ha infatti una semplice interpretazione geometrica.
Scopo di questo programma è mostrare questa cosa partendo da reti di piccole dimensioni, inutili dal punto di vista pratico, ma ottime dal punto di vista didattico!
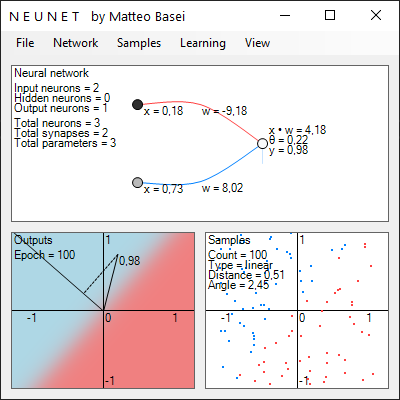
L'input space
L'elemento fondamentale per comprendere la rappresentazione geometrica delle reti neurali è l'input space, uno spazio vettoriale avente un asse per ogni singolo ingresso della rete. Se avete qualche nozione di meccanica razionale è un concetto molto simile allo spazio delle configurazioni. Effettivamente possiamo vederlo come lo spazio delle configurazioni degli input della rete. Ogni punto di questo spazio corrisponde a un possibile set di ingressi.
Se ad esempio gli ingressi della rete sono i 16 pixel di un'immagine 4 x 4 in scala di grigi avremo uno spazio vettoriale a 16 dimensioni. Ad ogni asse corrisponderà il valore (ad esempio da 0 a 255) di uno dei pixel dell'immagine. Ad un punto dello spazio, con le sue 16 coordinate, corrisponderanno i valori dei 16 pixel e il punto identificherà quindi univocamente uno dei possibili input, cioè una delle possibili immagini 4 x 4.
Il perceptron
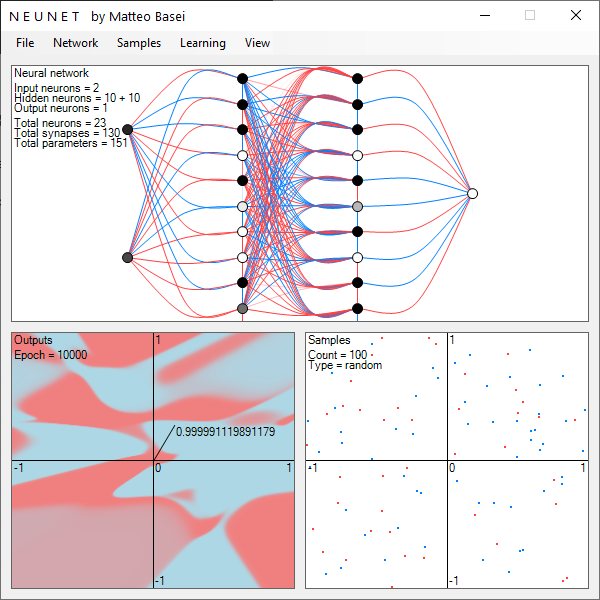
La semplice rete neurale per riconoscere cifre scritte a mano libera in immagini 20 x 20 citata all'inizio ha ben 400 ingressi (uno per ogni pixel dell'immagine) e 10 uscite (una per ogni cifra). Qui per semplicità, considereremo reti neurali con due ingressi e una singola uscita. Come vedremo considerando una singola uscita non si perde in generalità e con due ingressi si ha un input space bidimensionale, perfetto per essere rappresentato sullo schermo.
La più semplice rete di questo tipo è una funzione a 2 variabili, i 2 input che indicheremo con $x_1$ e $x_2$, e 3 parametri: i 2 pesi sinaptici $w_1$ e $w_2$ e la soglia di attivazione $\theta$ del neurone di uscita. Una rete di questo tipo viene chiamata perceptron in riferimento ad una delle prime realizzazioni di questo tipo, ottenuta da Frank Rosenblatt nel 1958 (anche se un modello di neurone artificiale era già stato proposto da McCulloch e Pitts nel 1943).
Tutto quello che può fare è suddividere gli input in due categorie separate da una retta. I pesi sinaptici regolano l'inclinazione della retta, la soglia di attivazione regola la posizione di tale retta rispetto all'origine dello spazio degli input. Consideriamo per semplicità una funzione di attivazione a gradino. In questo caso il neurone si attiva se $$ x \cdot w > \theta $$ dove a primo membro compare il prodotto scalare $$ x \cdot w = x_1 w_1 + x_2 w_2 $$ tra i vettori bidimensionali $x = \left[ x_1, x_2 \right]$ e $w = [w_1, w_2]$. Il prodotto scalare tra due vettori corrisponde geometricamente ad un numero proporzionale alla proiezione dell'uno sull'altro.
Generalizzando per un input space $n$-dimensionale e usando una funzione di attivazione $f$ l'uscita del neurone sarà $$ y = f \left( x \cdot w - \theta \right) $$ dove $$ x \cdot w = \sum_{i = 1}^n x_i w_i $$ In questo caso il perceptron potrà classificare gli ingressi dividento l'ipervolume $n$-dimensionale in due parti divise da un iperpiano $\left( n - 1 \right)$-dimensionale.
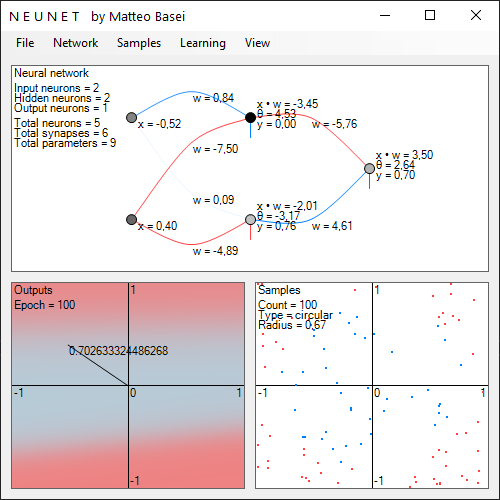
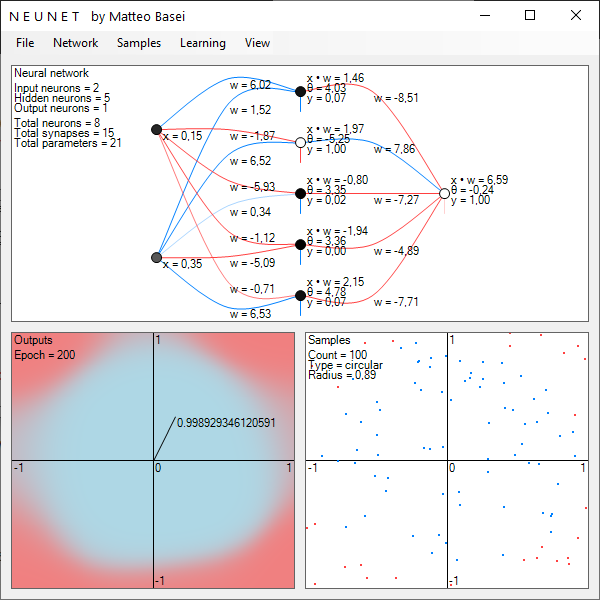
Gli hidden layer
Aggiungere un singolo neurone nascosto non porta a nessuna conseguenza, essendo essenzialmente la medesima cosa di aggiungere un singolo neurone a valle del neurone di uscita. Questo ulteriore neurone non potrà fare altro che suddividere linearmente la singola uscita a cui è collegato.
Aumentando il numero di neuroni nello strato nascosto è invece possibile delineare forme via via più complesse, quindi ottenere reti in grado di classificare distribuzioni via via più complesse di dati. In particolare il teorema di approssimazione universale dimostra che una rete neurale con un singolo strato nascosto con un numero sufficiente (e finito) di neuroni può approssimare qualsiasi funzione continua. Il teorema fu dimostrato nel 1989 da parte di George Cybenko.
Il teorema di approssimazione universale è un teorema di esistenza, afferma che una rete con un singolo strato nascosto può approssimare qualsiasi funzione continua, ma non da alcuna indicazione su come ottenerla, come istruirla e se un singolo strato sia la scelta più efficiente.
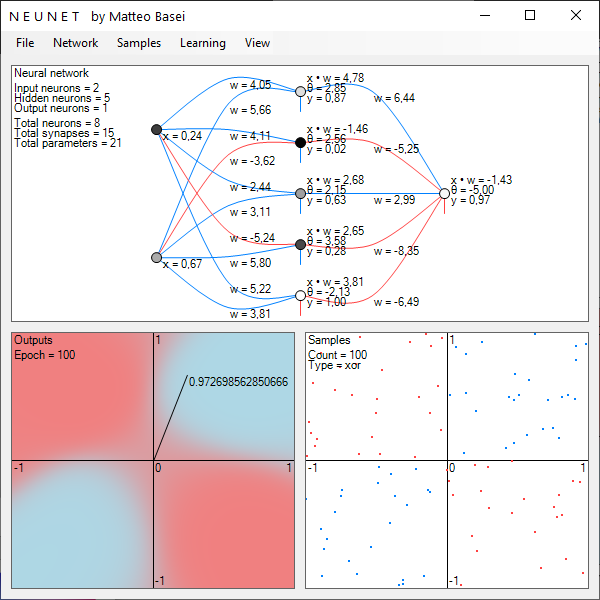
L'apprendimento
L'apprendimento per una rete neurale consiste in sostanza nella determinazione dei pesi sinaptici e delle soglie di attivazione. Anche l'algoritmo che si occupa di questo aspetto ha una semplice ed interessante interpretazione geometrica, che ho cerco di spiegare nel modo più semplice e dettagliato possibile in questa pagina.
Deep learning
[...]
Reti convoluzionali e long short term memory
In questa pagina abbiamo sempre parlato di un tipo di reti neurali chiamate feedforward fully connected, vale a dire reti neurali in cui:
- i neuroni sono organizzati a layer in cui non ci sono collegamenti a loop (né tra layer differenti, né all'interno dello stesso layer);
- non si fanno ipotesi a priori, quindi si collegano tutti i neuroni di un layer a tutti i neuroni del layer precedente.
Attualmente queste reti sono importanti principalmente da un punto di vista didattico o come parti di reti più complesse.
La comprensione di questo tipo di reti è un prerequisito per la comprensione di quelle da esse derivate, in cui queste due ipotesi vengono meno. Attualmente i tipi di rete neurale che vanno per la maggiore sono le reti convoluzionali (che non sono fully connected) e le long short term memory (un tipo particolare di rete ricorrente, quindi con collegamenti a loop).