NeuNet: backpropagation l'apprendimento è una biglia che rotola
"Chiedersi se i computer possano pensare è rilevante tanto quanto chiedersi se i sottomarini possano nuotare."
Lavorando ad alcuni miei programmi didattici sulle reti neurali (come NeuNet, che cerca di mostrare l'interpretazione geometrica dietro al funzionamento delle reti neurali, e NeuNet: digits recognizer, una piccola rete neurale in grado di riconoscere cifre scritte a mano libera) mi è venuta voglia di provare a mettere nero su bianco l'algoritmo di retropropagazione degli errori (in inglese backward propagation of errors, abbreviato in backpropagation), cioè l'algoritmo usato per l'apprendimento supervisionato delle reti neurali feedforward.
Ho cercato di farlo nel modo più semplice e diretto possibile, cercando di mostrare e spiegare tutti i passaggi e di derivare tutte le formule. Prerequisito per questa spiegazione è la conoscenza di come funziona una rete neurale e qualche base di analisi (sapere cos'è una derivata parziale e poco più).
La funzione di costo
Sia $w_{ijk}$ il $k$-esimo peso sinaptico del $j$-esimo neurone dell'$i$-esimo strato di una rete neurale feedforward fully connected e $\theta_{ij}$ la soglia di attivazione del medesimo neurone. Gli strati sono enumerati a ritroso a partire dallo strato di uscita a cui associamo l'indice $0$. Consideriamo una funzione $\varphi$ chiamata funzione di costo, avente come variabili tutti i pesi sinaptici $w_{ijk}$ e le soglie di attivazione $\theta_{ij}$, il cui valore corrisponde all'errore commesso dalla rete rispetto al valore atteso.
Si calcola il gradiente di questa funzione per individuare (localmente) la direzione che minimizza la funzione, quindi che minimizza l'errore. Lo scopo è raggiungere il minimo globale della funzione, che corrisponderà ai valori dei pesi sinaptici e delle soglie di attivazione che diano il minimo errore rispetto ai valori attesi. Per evitare di rimanere bloccati in un minimo locale si utilizza un fattore di "inerzia". Stiamo a tutti gli effetti facendo rotolare una biglia giù per la funzione, sperando che finisca nel punto più basso. Questa tecnica per l'aggiornamento dei pesi sinaptici si chiama discesa del gradiente. L'implementazione specifica per attuarla è detto algoritmo di retropropagazione degli errori.
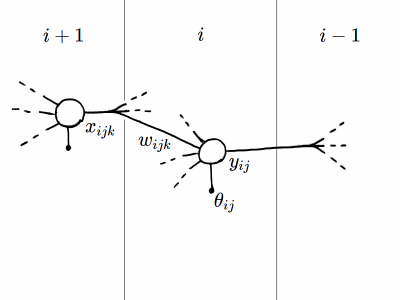
Indichiamo con $Y_{0j}$ il valore atteso per il $j$-esimo neurone dello strato di uscita. Per comodità ricapitoliamo le altre grandezze in gioco, che sono \begin{equation} \begin{alignedat}{2} x_{ijk} &\rightarrow \text{$k$-esimo ingresso del $j$-esimo neurone dell'$i$-esimo strato} \\ w_{ijk} &\rightarrow \text{corrispondente peso sinaptico} \\ \theta_{ij} &\rightarrow \text{soglia di attivazione} \\ z_{ij} &= \sum_k x_{ijk} w_{ijk} − \theta_{ij} \\ y_{ij} &= f(z_{ij}) \end{alignedat} \label{Ricapitoliamo} \end{equation} dove $f$ è la funzione di attivazione. Per lo strato di uscita si ha inoltre $$ \begin{alignedat}{2} Y_{0j} &\rightarrow \text{valore atteso} \\ \varphi &= \frac{1}{2} \left( y_{0j} − Y_{0j} \right)^2 \end{alignedat} $$
I termini del gradiente dello strato di uscita
Il gradiente di una funzione a $n$ variabili è un vettore $n$-dimensionale le cui componenti sono le derivate parziali della funzione rispetto a ciascuna delle sue variabili. In questo caso il gradiente della funzione $\varphi$ è costituito quindi dalle derivate parziali rispetto ad ogni peso sinaptico e ad ogni soglia di attivazione, vale a dire dai termini $\partial \varphi / \partial w_{ijk}$ e $\partial \varphi / \partial \theta_{ij}$, uno per ogni $w_{ijk}$ e ogni $\theta_{ij}$.
Per calcolare queste derivate partiamo dal fatto che l'errore commesso dalla rete dipende dai valori di uscita della rete stessa, cioè $\varphi$ dipende dalle $y_{ij}$, e quindi per la regola della catena possiamo scrivere $$ \begin{alignedat}{2} \frac{\partial \varphi}{\partial w_{ijk}} &= \frac{\partial \varphi}{\partial y_{ij}} \frac{\partial y_{ij}}{\partial w_{ijk}} \\[1ex] \frac{\partial \varphi}{\partial \theta_{ij}} &= \frac{\partial \varphi}{\partial y_{ij}} \frac{\partial y_{ij}}{\partial \theta_{ij}} \end{alignedat} $$ Per calcolare le derivate parziali $\partial y_{ij} / \partial w_{ijk}$ e $\partial y_{ij} / \partial \theta_{ij}$ sfruttiamo invece il fatto che i valori di uscita dipendono dall'argomento della funzione di attivazione, cioè le $y_{ij}$ dipendono dalle $z_{ij}$, quindi utilizzando nuovamente la regola della catena scriviamo $$ \begin{alignedat}{2} \frac{\partial \varphi}{\partial w_{ijk}} &= \frac{\partial \varphi}{\partial y_{ij}} \frac{\partial y_{ij}}{\partial z_{ij}} \frac{\partial z_{ij}}{\partial w_{ijk}} \\[1ex] \frac{\partial \varphi}{\partial \theta_{ij}} &= \frac{\partial \varphi}{\partial y_{ij}} \frac{\partial y_{ij}}{\partial z_{ij}} \frac{\partial z_{ij}}{\partial \theta_{ij}} \end{alignedat} $$ A questo punto possiamo calcolare facilmente i vari termini ottenuti come derivate elementari delle definizioni \eqref{Ricapitoliamo} $$ \frac{\partial y_{ij}}{\partial z_{ij}} = \frac{\partial}{\partial z_{ij}} \left( f(z_{ij}) \right) = f'(z_{ij}) $$ $$ \frac{\partial z_{ij}}{\partial w_{ijk}} = \frac{\partial}{\partial w_{ijk}} \left( \sum_k x_{ijk} w_{ijk} − \theta_{ij} \right) = x_{ijk} $$ $$ \frac{\partial z_{ij}}{\partial \theta_{ij}} = \frac{\partial}{\partial \theta_{ij}} \left( \sum_k x_{ijk} w_{ijk} − \theta_{ij} \right) = -1 $$ dove $f'$ è la derivata della funzione di attivazione del neurone. La necessità di calcolare la derivata di $f$ è il motivo per cui non si usa la funzione a gradino come funzione di attivazione, ma funzioni differenziabili come la sigmoide o la tangente iperbolica.
Per lo strato di uscita di cui possiamo calcolare anche $$ \frac{\partial \varphi}{\partial y_{0j}} = y_{0j} - Y_{0j} $$ otteniamo quindi \begin{equation} \begin{alignedat}{2} \frac{\partial \varphi}{\partial w_{0jk}} &= \left( y_{0j} - Y_{0j} \right) f'(z_{0j}) x_{0jk} \\[1ex] \frac{\partial \varphi}{\partial \theta_{0j}} &= -\left( y_{0j} - Y_{0j} \right) f'(z_{0j}) \end{alignedat} \label{GradienteStratoUscita} \end{equation} che ci permette di calcolare tutti i termini del gradiente relativi a pesi sinaptici e soglie di attivazione dei neuroni dello strato di uscita.
I termini del gradiente dei rimanenti strati
Le \eqref{GradienteStratoUscita} valgono per i neuroni dello strato di uscita, per i quali disponiamo direttamente dei valori attesi $Y_{0j}$. Per i neuroni degli strati nascosti l'unico termine che non possiamo calcolare sarà quello corrispondente a quello in cui compare $Y_{0j}$, vale a dire $\partial \varphi / \partial y_{0j} = y_{0j} − Y_{0j}$, quindi $\partial \varphi / \partial y_{ij}$.
Per ricavare il valore di tale termine partiamo dal fatto che dai valori di uscita $y_{ij}$ dipendono tutti i valori di uscita dello strato $i - 1$. Scriviamo quindi la derivata $\partial \varphi / \partial y_{ij}$ nella forma $$ \frac{\partial \varphi}{\partial y_{ij}} = \sum_k \frac{\partial \varphi}{\partial y_{(i - 1)k}} \frac{\partial y_{(i - 1)k}}{\partial y_{ij}} $$ dove abbiamo sommato su tutti i neuroni dello strato $i − 1$. Per la derivata $\partial y_{(i - 1)k} / \partial y_{ij}$ sfruttiamo ancora il fatto che $y_{(i - 1)k}$ dipende da $z_{(i - 1)k}$, quindi $$ \frac{\partial \varphi}{\partial y_{ij}} = \sum_k \frac{\partial \varphi}{\partial y_{(i - 1)k}} \frac{\partial y_{(i - 1)k}}{\partial z_{(i - 1)k}} \frac{\partial z_{(i - 1)k}}{\partial y_{ij}} $$ I termini $$ \frac{\partial \varphi}{\partial y_{(i - 1)k}} \frac{\partial y_{(i - 1)k}}{\partial z_{(i - 1)k}} $$ saranno semplicemente quelli calcolati nello step precedente, che nel caso dello strato di uscita sono $\left( y_{0k} - Y_{0k} \right) f'(z_{0k})$.
Da qui si comprende il nome dell'algoritmo. Partiamo a calcolare i termini del gradiente dallo strato di uscita, di cui conosciamo i valori attesi, e poi procediamo a ritroso. Ogni volta che calcoliamo i termini dello strato $i$ avremo già calcolato e messo da parte i valori dello strato $i - 1$.
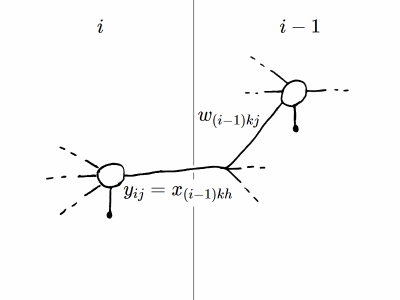
Per il terzo termine $\partial z_{(i - 1)k} / \partial y_{ij}$ partiamo dal fatto che nello strato precedente si ha $$ z_{(i - 1)k} = \sum_h x_{(i - 1)kh} w_{(i - 1)kh} − \theta_{(i - 1)k} $$ (che non è altro che la definizione di $z_{ij}$ per il neurone $k$ dello strato $i - 1$). Nei termini della sommatoria sugli ingressi del $k$-esimo neurone dello strato $i - 1$, uno corrisponde all'uscita del $j$-esimo neurone dello strato $i$, cioè per $h = j$ si ha $x_{(i - 1)kh} = y_{ij}$ e quindi la derivata cercata è semplicemente $$ \frac{\partial z_{(i - 1)k}}{\partial y_{ij}} = w_{(i - 1)kj} $$ poiché tutti gli altri termini della sommatoria e la soglia di attivazione $\theta_{(i - 1)k}$ hanno derivata rispetto ad $y_{ij}$ pari a $0$. Possiamo ora scrivere la formula per il termine $\partial \varphi / \partial y_{ij}$ anche per gli strati nascosti, che risulta $$ \frac{\partial \varphi}{\partial y_{ij}} = \sum_k \frac{\partial \varphi}{\partial y_{(i - 1)k}} \frac{\partial y_{(i - 1)k}}{\partial z_{(i - 1)k}} w_{(i - 1)kj} $$ dove compaiono i pesi sinaptici (noti) e le derivate parziali dello strato $i - 1$ che, procedendo a ritroso strato per strato, abbiamo già calcolato. I termini del gradiente per gli strati nascosti scritti per esteso sono quindi \begin{equation} \begin{alignedat}{2} \frac{\partial \varphi}{\partial w_{ijk}} &= \underbrace{\sum_l \overbrace{\frac{\partial \varphi}{\partial y_{(i - 1)l}} \frac{\partial y_{(i - 1)l}}{\partial z_{(i - 1)l}}}^\text{dallo strato precedente} w_{(i - 1)lj} f'(z_{ij})}_\text{per lo strato successivo} x_{ijk} \\[1ex] \frac{\partial \varphi}{\partial \theta_{ij}} &= -\underbrace{\sum_k \overbrace{\frac{\partial \varphi}{\partial y_{(i - 1)k}} \frac{\partial y_{(i - 1)k}}{\partial z_{(i - 1)k}}}^\text{dallo strato precedente} w_{(i - 1)kj} f'(z_{ij})}_\text{per lo strato successivo} \end{alignedat} \label{GradienteStratiNascosti} \end{equation} dove abbiamo evidenziato i termini che provengono dall'elaborazione dello strato precedente e quelli che vanno messi da parte per lo strato successivo.
Volendo sintetizzare l'algoritmo in una singola formula, evidenziando al contempo la sua natura iterativa (a ritroso) sugli strati, basta notare che durante l'elaborazione dello strato $i$ i termini che vengono messi da parte per lo strato $i + 1$ sono in effetti $\partial \varphi / \partial z_{ij}$, cioè la parte in comune delle \eqref{GradienteStratiNascosti}. Riscrivendo tali termini esplicitando nella sommatoria i medesimi termini dello strato $i - 1$ si ottiene $$ \frac{\partial \varphi}{\partial z_{ij}} = \sum_k \frac{\partial \varphi}{\partial z_{(i - 1)k}} w_{(i - 1)kj} f'(z_{ij}) $$ Questa equazione può essere considerata l'equazione fondamentale per il calcolo del gradiente della funzione di costo, infatti da sola, insieme alle derivate elementari per $\partial z_{ij} / \partial w_{ijk}$ e $\partial z_{ij} / \partial \theta_{ij}$ (rispettivamente $x_{ijk}$ e $-1$) e al fatto che per lo strato di uscita si ha $\partial \varphi / \partial z_{0j} = \left( y_{0j} - Y_{0j} \right) f'(z_{0j})$, è sufficiente per eseguire tutti i calcoli necessari.
L'aggiornamento dei pesi sinaptici e delle soglie di attivazione
Siamo ora pronti ad aggiornare i pesi sinaptici e le soglie di attivazione della nostra rete. Le equazioni \eqref{GradienteStratoUscita} e \eqref{GradienteStratiNascosti} ci permettono infatti di calcolare tutti i termini del gradiente, vale a dire tutti i termini $\partial \varphi / \partial w_{ijk}$ e $\partial \varphi / \partial \theta_{ij}$, uno per ogni $w_{ijk}$ e ogni $\theta_{ij}$.
Non resta che introdurre i due parametri che regolano l'apprendimento, che sono $$ \begin{alignedat}{2} \lambda &\rightarrow \text{tasso di apprendimento (learning rate)} \\[1ex] \mu &\rightarrow \text{inerzia (momentum)} \end{alignedat} $$ Il primo indica quanto velocemente vogliamo far rotolare giù la nostra biglia, il secondo la sua inerzia, che le permetterà di saltar fuori dai minimi locali che potrebbe incontrare nel suo percorso. Le variazioni dei pesi sinaptici e delle soglie di attivazione saranno nella direzione opposta al gradiente, che indica la direzione in cui la funzione aumenta, quindi $$ \begin{alignedat}{2} \delta w_{ijk} &= -\frac{\partial \varphi}{\partial w_{ijk}} \lambda \\[1ex] \delta \theta_{ij} &= -\frac{\partial \varphi}{\partial \theta_{ij}} \lambda \end{alignedat} $$ inoltre indichiamo le variazioni del ciclo di apprendimento precedente con $$ \begin{alignedat}{2} \delta w'_{ijk} &\rightarrow \text{$\delta w_{ijk}$ precedente} \\[1ex] \delta \theta'_{ij} &\rightarrow \text{$\delta \theta_{ij}$ precedente} \end{alignedat} $$ Non ci resta che aggiornare i valori $$ \begin{alignedat}{2} w_{ijk} &= w_{ijk} + \delta w_{ijk} + \mu \, \delta w'_{ijk} \\[1ex] \theta_{ij} &= \theta_{ij} + \delta \theta_{ij} + \mu \, \delta \theta'_{ij} \end{alignedat} $$ e ricominciare da capo!